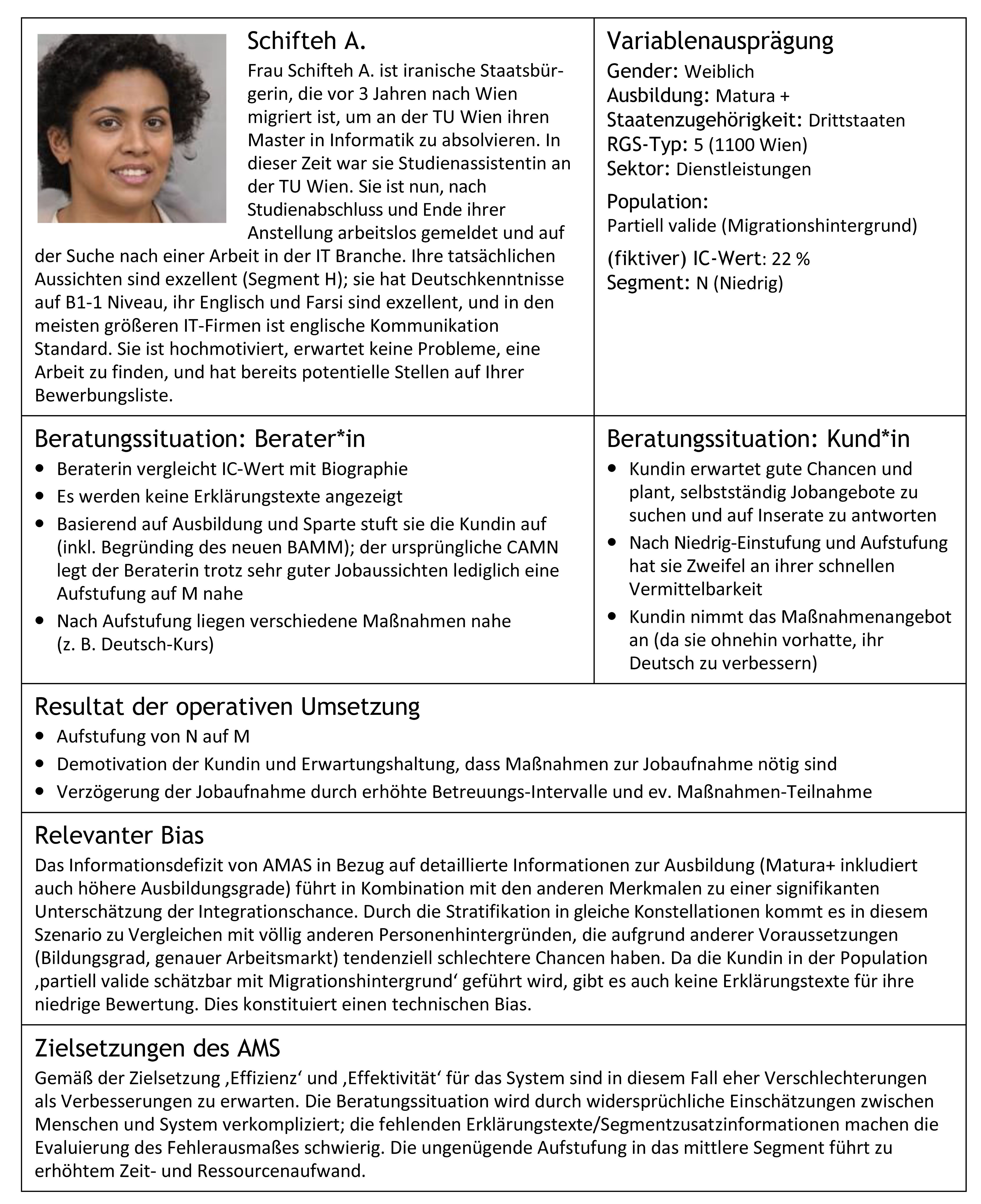
Finally, our report of the project on the so-called AMS-algorithm is out!!! YAY!!! It was a lot of work, but it was definitely worth it! It is an in-depth sociotechnical analysis and deconstruction of the algorithm the Austrian public employment service (AMS) is planning to roll out all over Austria starting from January 2021. The algorithm poses several severe challenges on both the institutional level and the larger societal level, as we – Doris Allhutter, Florian Cech, Fabian Fischer and Gabriel Grill – argued in our report. We’d like to thank the Upper Austrian Chamber of Labor (AK OÖ) that financed our study and particularly Dennis Tamesberger for his support throught the process. Here you can download the full report.
 The report triggered lots of media coverage, e.g. in APA Science or at orf.at. We also did some interviews, e.g. for the Austrian Academy of Sciences, Futurezone or the radio broadcast Ö1 (all in German). The final report is in German, but english publications will (hopefully) follow SOON! For now I’d like to point you to the english publications in New Frontiers in Big Data that we published a year ago (only based on publicly available materials back then, but still relevant in its argumentation):
The report triggered lots of media coverage, e.g. in APA Science or at orf.at. We also did some interviews, e.g. for the Austrian Academy of Sciences, Futurezone or the radio broadcast Ö1 (all in German). The final report is in German, but english publications will (hopefully) follow SOON! For now I’d like to point you to the english publications in New Frontiers in Big Data that we published a year ago (only based on publicly available materials back then, but still relevant in its argumentation):
Allhutter, D., Cech, F., Fischer, F., Grill, G. & Mager, A. (2020) “Algorithmic Profiling of Job Seekers in Austria: How Austerity Politics Are Made Effective”, Frontiers in Big Data (Special Issue Critical Data and Algorithm Studies), full text; open access here.